


L'emergere della tecnologia informatica nel nostrola modernità ha segnato una rivoluzione dell'informazione in tutti gli ambiti dell'attività umana. Ma per evitare che tutte le informazioni diventino spazzatura inutile su Internet globale, è stato inventato un sistema di database, in cui i materiali vengono ordinati, sistematizzati, in conseguenza del quale possono essere facilmente trovati e presentati per la successiva elaborazione. Esistono tre tipi principali: database relazionali, gerarchico, di rete.
Tornando alle origini dei database, ne vale la penaper dire che questo processo era piuttosto complesso, ha origine con lo sviluppo di apparecchiature di elaborazione delle informazioni programmabili. Pertanto, non sorprende che il numero dei loro modelli al momento raggiunga più di 50, ma i principali sono considerati gerarchici, relazionali e di rete, che sono ancora ampiamente utilizzati nella pratica. Quali sono?
Il database gerarchico ha una struttura ad alberostruttura ed è composto da dati di diversi livelli, tra i quali ci sono collegamenti. Il modello di rete DB è un modello più complesso. La sua struttura assomiglia a una gerarchica e lo schema è ampliato e migliorato. La differenza tra loro è che i dati ereditari di un modello gerarchico possono avere una connessione con un solo antenato, mentre i dati di rete possono averne diversi. La struttura di un database relazionale è molto più complessa. Pertanto, dovrebbe essere analizzato in modo più dettagliato.

Questo modello è stato sviluppato negli anni '70.di Edgar Codd, Dottore in Scienze. È una tabella strutturata logicamente con campi che descrivono i dati, le loro relazioni tra loro, le operazioni eseguite su di essi e, soprattutto, le regole che ne garantiscono l'integrità. Perché il modello si chiama relazionale? Si basa sulle relazioni (dal lat. Relatio) tra i dati. Esistono molte definizioni per questo tipo di database. Le tabelle relazionali con informazioni sono molto più facili da organizzare ed elaborare rispetto a un modello di rete o gerarchico. Come si può fare? Basta conoscere le caratteristiche, la struttura del modello e le proprietà delle tabelle relazionali.

Per creare il tuo DBMS, dovrestiutilizzare uno degli strumenti di modellazione, pensare a quali informazioni è necessario lavorare, progettare tabelle e relazioni relazionali singole e multiple tra i dati, compilare celle di entità e impostare chiavi primarie esterne.
Modellazione di tabelle e progettazione relazionalei database sono prodotti tramite strumenti gratuiti come Workbench, PhpMyAdmin, Case Studio, dbForge Studio. Dopo la progettazione dettagliata, è necessario salvare il modello relazionale graficamente pronto e tradurlo in codice SQL già pronto. In questa fase, puoi iniziare a lavorare con l'ordinamento, l'elaborazione e la sistematizzazione dei dati.
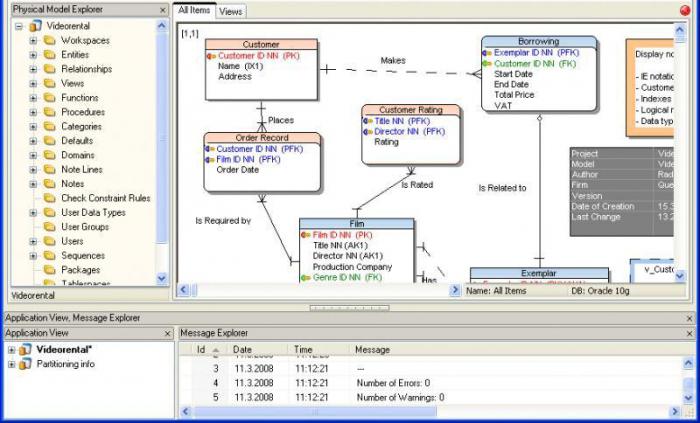
Ogni fonte descrive i suoi elementi a modo suo, quindi per meno confusione vorrei dare un piccolo suggerimento:

Per accedere alle proprietà di un database relazionale, è necessario sapere di quali componenti di base è costituito ea cosa servono.
Ora, conoscendo gli elementi costitutivi della tabella, puoi andare alle proprietà del modello relazionale del database:
In base alle proprietà di un DBMS relazionale, è chiaro che i valori degli attributi devono essere dello stesso tipo e lunghezza. Consideriamo le caratteristiche dei valori degli attributi.
I nomi dei campi devono essere univoci all'interno diun'entità. Gli attributi oi tipi di campo del database relazionale descrivono quali dati di categoria sono archiviati nei campi entità. Un campo di database relazionale deve avere una dimensione fissa in caratteri. I parametri e il formato dei valori degli attributi determinano il modo in cui i dati vengono corretti in essi. C'è anche qualcosa come "maschera" o "schema di input". Ha lo scopo di definire la configurazione dell'immissione dei dati nel valore dell'attributo. È fondamentale che venga emesso un messaggio di errore durante la scrittura di un tipo di dati errato in un campo. Inoltre, vengono imposte alcune restrizioni agli elementi dei campi: condizioni per il controllo dell'accuratezza e immissione dei dati senza errori. È presente un valore di attributo obbligatorio che deve essere popolato in modo univoco con i dati. Alcune stringhe di attributi possono essere riempite con valori NULL. È consentito immettere dati vuoti negli attributi del campo. Come la notifica di errore, ci sono valori che vengono compilati automaticamente dal sistema: questi sono i dati predefiniti. Un campo indicizzato ha lo scopo di accelerare la ricerca di qualsiasi dato.

| Nome attributo 1 | Nome attributo 2 | Nome attributo 3 | Nome attributo 4 | Nome attributo 5 |
| Item_1_1 | Item_1_2 | Item_1_3 | Item_1_4 | Item_1_5 |
| Item_2_1 | Item_2_2 | Item_2_3 | Item_2_4 | Item_2_5 |
| Item_3_1 | Item_3_2 | Item_3_3 | Item_3_4 | Articolo_3_5 |
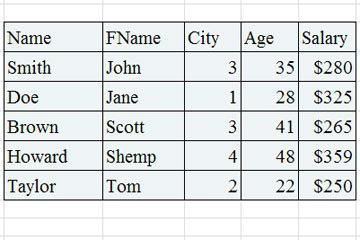
Per una comprensione dettagliata del sistema di controlloPer i modelli che utilizzano SQL, il modo migliore per esaminare lo schema è con l'esempio. Sappiamo già cos'è un database relazionale. Un record in ogni tabella è un elemento di dati. Per evitare la ridondanza dei dati, è necessario eseguire operazioni di normalizzazione.
1. Il valore del nome del campo per una tabella relazionale deve essere univoco, unico nel suo genere (la prima forma normale è 1NF).
2. Per una tabella che è già stata ridotta a 1NF, il nome di qualsiasi colonna non identificativa deve dipendere dall'identificatore univoco della tabella (2NF).
3. Per l'intera tabella che è già in 2NF, ogni campo non identificativo non può dipendere da un elemento di un altro valore non riconosciuto (entità 3NF).
Esistono 2 tipi principali di relazioni tra tabelle relazionali:

Le chiavi primarie e secondarie definisconopotenziali relazioni con il database. I collegamenti relazionali di un modello di dati possono avere solo una chiave potenziale, questa sarà la chiave primaria. Come è lui? Una chiave primaria è una colonna di entità o un insieme di attributi che consente di accedere ai dati per una determinata riga. Deve essere univoco, univoco e i suoi campi non possono contenere valori vuoti. Se la chiave primaria è costituita da un solo attributo, viene chiamata semplice, altrimenti sarà un componente.
Oltre alla chiave primaria, è presente anche una chiave esterna(chiave esterna). Molti non capiscono quale sia la differenza tra loro. Vediamoli più in dettaglio usando un esempio. Quindi, ci sono 2 tavoli: "Dean's office" e "Students". L'entità "Ufficio del preside" contiene i campi: "ID studente", "Nome completo" e "Gruppo". La tabella "Studenti" ha valori di attributo come "Nome", "Gruppo" e "Media". Poiché l'ID studente non può essere lo stesso per più studenti, questo campo sarà la chiave primaria. "Nome completo" e "Gruppo" della tabella "Studenti" possono essere uguali per più persone, si riferiscono al numero ID dello studente dall'entità "Preside", quindi possono essere utilizzati come chiave esterna.
Per chiarezza, daremo un semplice esempio di un modello di database relazionale costituito da due entità. C'è un tavolo chiamato "Deanery".
Essence "Deanery" | ||
ID studente | Nome e cognome | gruppo |
111 | Ivanov Oleg Petrovich | IN-41 |
222 | Ilya Lazarev | IN-72 |
333 | Konoplev Petr Vasilievich | IN-41 |
444 | Kushnereva Natalia Igorevna | IN-72 |
È necessario stabilire connessioni per otteneredatabase relazionale a tutti gli effetti. Il record "IN-41", come "IN-72", può essere presente più di una volta nella targa "Dean's office" e il cognome, il nome e il patronimico degli studenti in rari casi possono coincidere, quindi questi campi non possono essere ha reso la chiave primaria. Mostriamo l'entità "Studenti".
Tavolo "Studenti" | |||
Nome e cognome | gruppo | Voto medio | Numero di telefono |
Ivanov Oleg Petrovich | IN-41 | 3,0 | 2-27-36 |
Ilya Lazarev | IN-72 | 3,8 | 2-36-82 |
Konoplev Petr Vasilievich | IN-41 | 3,9 | 2-54-78 |
Kushnereva Natalia Igorevna | IN-72 | 4,7 | 2-65-25 |
Come possiamo vedere, i tipi di campi nei database relazionalicompletamente differente. Ci sono voci sia digitali che simboliche. Pertanto, i valori di integer, char, vachar, date e altri dovrebbero essere specificati nelle impostazioni degli attributi. Nella tabella "Ufficio del preside", solo l'ID studente è un valore univoco. Questo campo può essere utilizzato come chiave primaria. Il nome completo, il gruppo e il numero di telefono dell'entità "Studenti" possono essere utilizzati come chiave esterna che fa riferimento all'ID studente. La connessione è stata stabilita. Questo è un esempio di un modello di relazione uno a uno. Ipoteticamente, una delle tabelle è superflua, possono essere facilmente combinate in un'unica entità. Per evitare che i numeri ID studente diventino generalmente noti, l'esistenza di due tabelle è abbastanza realistica.


