


Darbā ar visizdevīgāko informācijuuzglabāšanas metodes ir struktūras un masīvi. Pēdējais var saturēt jebkura veida datus, kurus ir ērti lietot programmā. Tos bieži izmanto tiešsaistes veikalos un spēļu izstrādē. Tāpēc tajos esošie dati tiek atkārtoti kārtoti un apmainīti, un tiem tiek veiktas loģiskas vai matemātiskas operācijas. Viens veids, kā iztīrīt masīvu, ir burbuļu šķirošana. Šajā publikācijā tiks pārbaudīts tās C kods un permutācijas loģika.
Programmētāja tehniskās grūtībasviendimensiju masīva burbuļu šķirošana nepārstāv, kaut arī zemās efektivitātes dēļ to reti izmanto. Apmācības posmā to bieži uzskata par vienkāršāko. Tomēr tas nebūt nav visefektīvākais. Tās algoritms sastāv no skaitļu secīgas salīdzināšanas un šūnu pārrakstīšanas, ja nosacījums ir izpildīts.

Pirmajā iterācijā pakāpeniski salīdzina divusblakus esošie skaitļi. Ja kreisais ir lielāks, tad vietās ar labo pusi tas tiek pārrakstīts. Mīnus 8 un 0 nosacījumi neatbilst. Tāpēc viņi nemaina vietas. Nulle un 5 arī nav piemēroti. 5 un 3 ir piemēroti. Tomēr šādā atkārtojumā lasīšanas rāmis neietilpst pieciniekā, bet gan nobīdās pa labi, jo 5 iepriekš tika salīdzināti ar nulli. Tas nozīmē, ka nākamais pāris tiek apgriezts pretējā virzienā - 3. un 9. Tālāk lasītājs tiek aicināts aplūkot visus aizstājumus bez autoru komentāriem un izpētīt burbuļu šķirošanas algoritmu.
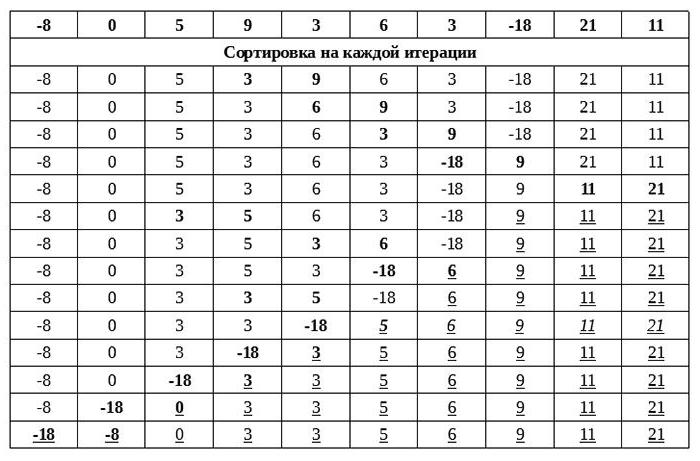
Visu atkārtojumu rezultātā masīvs tiek pakāpeniski izveidotssakārtoti, un tas notiek galvenokārt šādi: lieli pozitīvi skaitļi ātri pārvietojas pa labi, savukārt mazāki un negatīvi skaitļi tiek lēnām pārkārtoti pa kreisi. Izskatās, ka šķidruma gāzes burbuļi ātri uzpeld. Šīs analoģijas dēļ algoritmu sauca par burbuļu šķirošanu.
Идеальный алгоритм сортировки должен быть cik ātri vien iespējams. Tajā pašā laikā tam vajadzētu aizņemt nelielu daudzumu procesora un atmiņas resursu. Un tāds process kā masīva burbuļu šķirošana nevar būt energoefektīvākais un rentablākais. Tāpēc viņš neatrada plašu pielietojumu. Ja šobrīd ar atmiņu ir mazāk problēmu, jums jāuztraucas par procesora resursiem. Tā kā digitālie masīvi var būt ne tikai lieli, bet arī milzīgi, datora resursu patēriņš būs neparedzams.
Ja burbuļu šķirošana principā ir ātratikt galā ar kārtības atjaunošanu salīdzinoši nelielā masīvā, tad lielā var rasties kļūmes resursu pārmērīgas izmantošanas dēļ. Tas nozīmē, ka tiks pārkāpts algoritmam piemītošais universāluma īpašums. Turklāt šķirošanai pēc burbuļa ir N-kvadrāta sarežģītība un tas ir ļoti tālu no N sarežģītības logaritma. Turklāt kļūmes risks, apstrādājot lielu masīvu, palielina datu zaudēšanas iespējas šūnu pārrakstīšanas dēļ. Kārtošana pēc ieliktņiem vai Shell algoritms šajā ziņā būs daudz izdevīgāks.
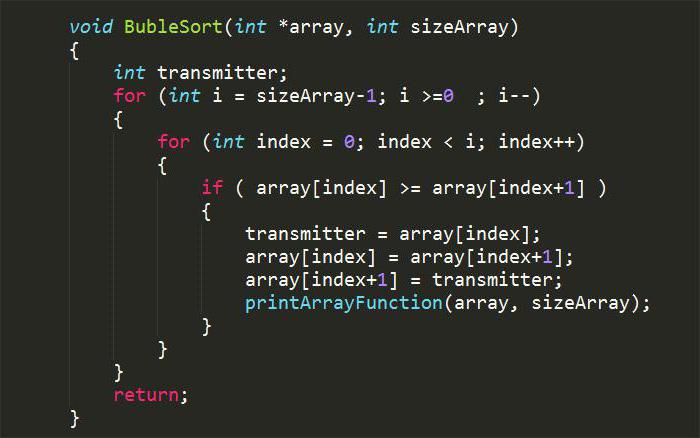
Norādīts zemāk grafiskajā pielietojumādatora kods C valodai ļauj veikt burbuļu kārtošanu. Tas tiek atveidots kā atsevišķa tukšuma veida funkcija. Tas neatgriež nevienu vērtību, bet izmanto norādes, lai mainītu vienumus, pamatojoties uz kārtošanas nosacījumiem. Šajā gadījumā kods atrisina problēmu ar burbuļu šķirošanu veselu skaitļu masīvā augošā secībā.
Lai veiktu šo funkciju, lietotājam irizveidojiet masīvu, kas jāaizpilda ar vēlamajām vērtībām. To var izdarīt manuāli, programmas sākumā iestatot izmēru un elementu skaitu. Tad jūs varat aizpildīt masīvu ar nemainīgām vērtībām. Otra iespēja ir izveidot universālu programmu, deklarējot lielu viendimensionālu 100 elementu masīvu.
Iestatot vesela skaitļa mainīgo un tam piešķirotno tastatūras nolasīto vērtību, varat ierobežot aizpildīto šūnu skaitu. Varat arī ieviest funkciju, lai lietotājs ievadītu masīva elementus no tastatūras, izmantojot funkciju scanf ("% d" un vērtība). Šajā piemērā "% d" ir modifikācijas virkne, kas kompilatoram saka, ka pēc skenēšanas tiks atgriezta vesela skaitļa vērtība. Mainīgā vērtība saglabās vērtību, kas ir viendimensionāla vesela skaitļa masīva lielums.
Lai izmantotu šķirošanas algoritmu, vajadzētunodot masīva nosaukumu un tā lielumu funkcijai. Grafiskā lietojumprogrammā parādītajā situācijā izsaukums uz šķirošanas funkciju izskatīsies šādi: BubleSort (dataArray, sizeDataArray). Protams, rindas beigās pēc funkcijas, perioda vietā ir jāievieto semikols, kā to prasa programmas sintakses noteikumi. Tātad dataArray ir kārtojamā masīva nosaukums un sizeDataArray ir tā lielums.

Šo parametru nodošana funkcijai BubleSort ()radīs faktu, ka tā vietā, lai izmantotu sizeArray, kā redzams attēlā, reālā programmā operācijas tiks veiktas ar sizeDataArray. Tas nozīmē arī to, ka funkcija BABLESORT () tiks izmantota veselā skaitļa masīvs dataArray. Funkcijas printArrayFunction () un ArrayIntegerInputFunction () tiek izsauktas vienādi. Pirmais ir atbildīgs par drukāšanu, tas ir, par priekšmetu parādīšanu konsolē. Un otrais ir vajadzīgs, lai to aizpildītu ar elementiem, kurus lietotājs ievadījis no tastatūras.
Šis programmēšanas stils, ja tas ir izolētsdarbības tiek veiktas funkciju veidā, ievērojami palielina koda lasāmību un paātrina tā attīstību. Šādā programmā atsevišķi tiek izņemta masīva aizpildīšana no tastatūras, tās drukāšana un pati burbuļu kārtošana. Pēdējo var izmantot datu pasūtīšanai vai kā papildu funkciju, lai atrastu masīva minimālo un maksimālo.
Ievietošanas kārtība tiek pieņemtapārmaiņus salīdzinot katru elementu un izveidojot jau nosacīti sakārtotu elementu ķēdi. Rezultātā katra nākamā salīdzinājuma rezultāts ir šūnas meklēšana, kurā var ievietot jaunu vērtību. Bet katra no tām tiek ievietota jau sakārtotajā masīva daļā.
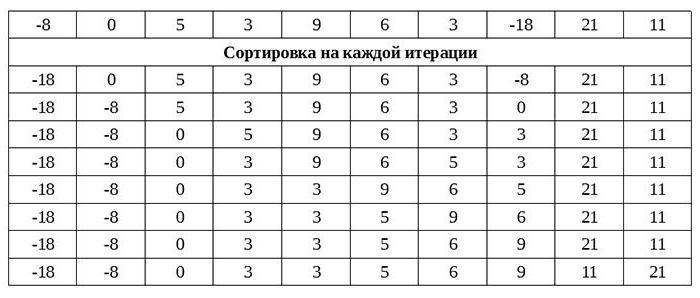
Šī apstrāde ir ātrāka un mazāk sarežģīta skaitļošanas jomā. C kods tiek parādīts grafiskā lietojumā.

Tas tiek atveidots arī kā funkcija, kurāpasūtītā masīva nosaukums un masīva lielums tiek nodoti kā argumenti. Šeit jūs varat redzēt, cik lēns ir burbuļu šķirošana. Ieliktņi līdzīgu darbu veic daudz ātrāk, un tiem ir kompakts programmas kods.


