


Kodowanie informacji - niewiarygodnie szerokiedziedzina wiedzy. Oczywiście wiąże się to bezpośrednio z rozwojem technologii cyfrowej. W wielu nowoczesnych instytucjach edukacyjnych najpopularniejszym tematem jest kodowanie informacji. Dzisiaj przyjrzymy się głównym interpretacjom tego zjawiska w odniesieniu do różnych aspektów działania komputerów. Spróbujmy odpowiedzieć na pytanie: „Czy kodowanie jest procesem, metodą, narzędziem, czy też wszystkimi tymi zjawiskami jednocześnie?”
Prawie każdy typ danych, którywyświetlane na ekranie komputera w taki czy inny sposób reprezentują kod binarny składający się z zer i jedynek. Jest to najprostsza, „niskopoziomowa” metoda szyfrowania informacji, umożliwiająca przetwarzanie danych przez komputer PC. Kod binarny jest uniwersalny: jest rozumiany przez wszystkie komputery bez wyjątku (w rzeczywistości do tego został stworzony - aby ujednolicić wykorzystanie informacji w formie cyfrowej).

Jednostka podstawowa używana w systemie binarnymkodowanie to bit (od wyrażenia „cyfra binarna” - „podwójna cyfra”). Jest to 0 lub 1. Z reguły bity nie są używane pojedynczo, ale są łączone w ciągi 8-cyfrowe - bajty. Tak więc każda z nich może zawierać do 256 kombinacji zer i jedynek (od 2 do 8. potęgi). Do rejestrowania znacznych ilości informacji z reguły nie używa się pojedynczych bajtów, ale większe ilości - z przedrostkami „kilo”, „mega”, „giga”, „tera” itp., z których każdy jest 1000 razy większy niż poprzedni...
Najpopularniejszą formą danych cyfrowych jesttekst. Jak to jest zakodowane? Jest to dość łatwy do wyjaśnienia proces. Literę, znak interpunkcyjny, cyfrę lub symbol można zakodować za pomocą jednego lub więcej bajtów, czyli komputer widzi je jako unikalny ciąg zer i jedynek, a następnie, zgodnie z wbudowanym algorytmem rozpoznawania, wyświetla je na ekran. Istnieją dwa główne światowe standardy "szyfrowania" tekstu komputerowego - ASCII i UNICODE.
W systemie ASCII każdy znak jest kodowany tylkojeden bajt. Oznacza to, że dzięki temu standardowi możliwe jest "zaszyfrowanie" do 256 znaków - co jest więcej niż wystarczające, aby wyświetlić znaki większości światowych alfabetów. Oczywiście wszystkie istniejące dziś krajowe systemy listowe nie będą pasować do tego zasobu. Dlatego każdy alfabet ma swój własny „podsystem” szyfrowania. Informacje są kodowane za pomocą systemów znaków dostosowanych do narodowych wzorców pisma. Jednak każdy z tych systemów z kolei stanowi integralną część globalnego standardu ASCII przyjętego na poziomie międzynarodowym.

W systemie ASCII ten sam zasób jest poza 256znaki są podzielone na dwie części. Pierwsze 128 to znaki zarezerwowane dla alfabetu angielskiego (litery od a do z), a także cyfry, podstawowa interpunkcja i kilka innych symboli. Drugie 128 bajtów jest z kolei zarezerwowane dla krajowych systemów listowych. Jest to „podsystem” dla alfabetów innych niż angielski - rosyjskiego, hindi, arabskiego, japońskiego, chińskiego i wielu innych.
Każdy z nich jest prezentowany jako osobnytabele kodowania. Oznacza to, że może się zdarzyć (i z reguły tak się dzieje), że ta sama sekwencja bitów będzie odpowiadać za różne litery i symbole w dwóch oddzielnych „narodowych” tabelach. Co więcej, ze względu na specyfikę rozwoju sfery IT w różnych krajach, nawet one się różnią. Na przykład dwa systemy kodowania są najbardziej powszechne dla języka rosyjskiego: Windows-1251 i KOI-8. Ten pierwszy pojawił się później (a także sam system operacyjny, który był z nim zgodny), ale teraz wielu informatyków używa go priorytetowo. Dlatego komputer musi być w stanie poprawnie rozpoznać obie tabele, aby można było zagwarantować odczytanie na nich tekstu rosyjskiego. Ale z reguły nie ma z tym problemów (jeśli komputer ma nowoczesny system operacyjny).
Techniki kodowania tekstu przez cały czaspoprawiają się. Oprócz „jednobajtowego” systemu ASCII, który obsługuje tylko 256 znaków, istnieje również „dwubajtowy” system UNICODE. Łatwo obliczyć, że pozwala na kodowanie tekstu w ilości równej 2 do potęgi 16, czyli 65 tys. 536. Posiada z kolei zasoby do jednoczesnego kodowania prawie wszystkich istniejących alfabetów narodowych świata . Użycie UNICODE jest nie mniej powszechne niż użycie „klasycznego” standardu ASCII.
Powyżej zdefiniowaliśmy sposób ich „szyfrowania”teksty i jak używane są bajty. A co ze zdjęciami i obrazami cyfrowymi? Również całkiem proste. Podobnie jak w przypadku tekstu, te same bajty odgrywają główną rolę w kodowaniu grafiki komputerowej.
Ogólnie o procesie obrazowania cyfrowegopodobny do mechanizmów, na podstawie których działa telewizor. Na ekranie telewizora, jeśli przyjrzysz się uważnie, obraz składa się z wielu pojedynczych kropek, które razem tworzą figury rozpoznawalne z pewnej odległości przez oko. Matryca telewizyjna (lub projektor CRT) odbiera z nadajnika współrzędne poziome i pionowe każdego z punktów i stopniowo buduje obraz. Zasada kodowania grafiki komputerowej działa w ten sam sposób. „Szyfrowanie” obrazów bajtami polega na ustawieniu każdego z punktów ekranu na odpowiednie współrzędne (a także kolor każdego z nich). To jest w prostych słowach. Oczywiście kodowanie graficzne jest procesem znacznie bardziej złożonym niż kodowanie tekstowe.
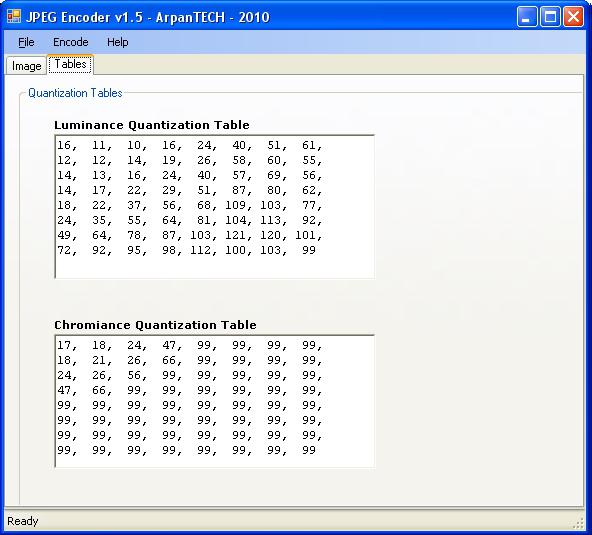
Sposób określenia punktów o odpowiednich współrzędnych iopcje kolorów nazywa się „mapą bitową”. Wiele formatów plików grafiki komputerowej ma podobne nazwy. Współrzędne każdego z punktów obrazu, a także ich kolor, są zapisywane w jednym lub kilku bajtach. Co decyduje o ich liczbie? Głównie od tego, ile odcieni koloru trzeba „zaszyfrować”. Jak wiesz, jeden bajt to 256 wartości. Jeśli wystarczy nam tyle odcieni do zbudowania obrazu, poradzimy sobie z tym zasobem. W szczególności możemy mieć do dyspozycji 256 odcieni szarości. A to wystarczy do zakodowania niemal każdego czarno-białego obrazu. Z kolei ten zasób oczywiście nie wystarczy do kolorowych obrazów: wiadomo, że ludzkie oko jest w stanie rozróżnić nawet kilkadziesiąt milionów kolorów. Dlatego potrzebna jest „rezerwa” nie w 256 wartościach, ale setki tysięcy razy więcej. Dlatego do kodowania punktów nie używa się jednego bajtu, ale kilka bajtów: zgodnie z obowiązującymi dziś standardami może być ich 16 (można "zaszyfrować" 65 tysięcy 536 kolorów) lub 24 (16 milionów 777 tysięcy 216 odcieni) .
W przeciwieństwie do standardów tekstowych różnorodnośćco jest porównywalne z liczbą języków świata, z grafiką sytuacja jest nieco prostsza. Najpopularniejsze formaty plików (takie jak JPEG, PNG, BMP, GIF itp.) są ogólnie równie dobrze rozpoznawane na większości komputerów.
Nie ma nic trudnego, aby zrozumieć jakzasady to kodowanie informacji graficznych. Dziewiąta klasa każdej rosyjskiej szkoły średniej obejmuje z reguły kurs informatyki, w którym takie technologie są szczegółowo ujawniane w bardzo prostym i zrozumiałym języku. Istnieją również specjalistyczne programy szkoleniowe dla dorosłych – organizowane są przez uczelnie, licea, a także szkoły.

Dlatego współczesny Rosjanin magdzie zdobyć wiedzę o kodach mających praktyczne znaczenie z punktu widzenia grafiki komputerowej. A jeśli chcesz samodzielnie zapoznać się z podstawową wiedzą, możesz zaopatrzyć się w przystępne materiały dydaktyczne. Należą do nich np. rozdział „Kodowanie informacji graficznej (klasa 9, podręcznik „Informatyka i ICT” autorstwa ND Ugrinovicha).
Komputer jest regularnie używany dosłuchanie muzyki i innych plików audio. Podobnie jak w przypadku tekstu i grafiki, każdy dźwięk na komputerze ma te same bajty. Te z kolei są „odszyfrowywane” przez kartę dźwiękową i inne mikroukłady i zamieniane na dźwięk słyszalny. Zasada jest tutaj w przybliżeniu taka sama jak w przypadku płyt gramofonowych. W nich, jak wiadomo, każdemu dźwiękowi odpowiada mikroskopijny rowek na plastiku, który jest rozpoznawany przez czytelnika, a następnie brzmiony. W komputerze wszystko jest podobne. Jedynie rolę rowków pełnią bajty, których charakter, podobnie jak w przypadku tekstu i obrazów, polega na kodowaniu binarnym.

Jeśli w przypadku obrazów komputerowychpunkt jest pojedynczym elementem, to przy nagrywaniu dźwięku jest to tzw. „liczenie”. Z reguły zapisywane są w nim dwa bajty, generujące do 65 tys. 536 mikrodrgań dźwiękowych. Jednak w przeciwieństwie do tego, jak to się dzieje przy budowaniu obrazów, aby poprawić jakość dźwięku, nie dodaje się dodatkowych bajtów (jest ich oczywiście aż nadto), ale zwiększa się ilość „próbek”. Chociaż niektóre systemy audio wykorzystują zarówno mniej, jak i więcej bajtów. Gdy trwa kodowanie dźwięku, standardową jednostką miary „gęstości strumienia” bajtów jest jedna sekunda. Oznacza to, że mikrowibracje zakodowane z 8 tysiącami próbek na sekundę będą oczywiście gorszej jakości niż sekwencja dźwięków zakodowana z 44 tysiącami „próbek”.
Międzynarodowa standaryzacja plików audio, podobnie jak w przypadku grafiki, jest dobrze rozwinięta. Istnieje kilka typowych formatów mediów audio - MP3, WAV, WMA - używanych na całym świecie.
Rodzaj „schematu hybrydowego”, w którymszyfrowanie dźwięku jest połączone z kodowaniem obrazu, stosowanym w wideo komputerowych. Zazwyczaj filmy i klipy składają się z dwóch rodzajów danych — samego dźwięku i towarzyszącej mu sekwencji wideo. Opisaliśmy powyżej, w jaki sposób pierwszy składnik jest „zaszyfrowany”. Drugi jest trochę trudniejszy. Zasady tutaj są inne niż te zawarte w powyższym kodowaniu graficznym. Ale ze względu na uniwersalność „pojęcia” bajtów istota mechanizmów jest dość jasna i logiczna.
Pamiętajmy, jak ułożony jest film.To nic innego jak sekwencja oddzielnych klatek (z reguły jest ich 24). Filmy komputerowe są ułożone dokładnie w ten sam sposób. Każda ramka to obrazek. Jak jest zbudowany przy użyciu bajtów, zdefiniowaliśmy powyżej. Z kolei w sekwencji wideo znajduje się pewien obszar kodu, który pozwala na łączenie ze sobą poszczególnych klatek. Rodzaj cyfrowego substytutu filmu. Za oddzielną jednostkę miary dla strumienia wideo (podobną do punktów dla obrazów i próbek dźwięku, jak w „filmowym” formacie filmów i klipów) uważa się ramkę. Te ostatnie w ciągu jednej sekundy, zgodnie z przyjętymi standardami, mogą wynosić 25 lub 50.
Podobnie jak w przypadku dźwięku, jestwspólne międzynarodowe standardy plików wideo - MP4, 3GP, AVI. Producenci filmowi i komercyjni starają się tworzyć próbki mediów, które są kompatybilne z jak największą liczbą komputerów. Te formaty plików należą do najpopularniejszych i można je otwierać na prawie każdym nowoczesnym komputerze.
Przechowywanie danych komputerowych odbywa się naróżne nośniki - dyski, dyski flash itp. Jak powiedzieliśmy powyżej, bajty z reguły są „zarośnięte” przedrostkami „mega”, „giga”, „tera” itp. W niektórych przypadkach rozmiar zaszyfrowanych plików jest to, że nie da się ich umieścić z dostępnymi zasobami na dysku. Następnie wykorzystywane są różnego rodzaju metody kompresji danych. W rzeczywistości są również kodowaniem. To kolejna możliwa interpretacja tego terminu.
Istnieją dwa główne mechanizmy kompresji danych.W przypadku pierwszego z nich sekwencja bitów jest zapisywana w postaci „pakowanej”. Oznacza to, że komputer nie może odczytać zawartości plików (odtworzyć jej jako tekstu, obrazu lub wideo), jeśli nie wykona procedury „rozpakowania”. Program, który kompresuje dane w ten sposób, nazywany jest archiwizatorem. Zasada jego działania jest dość prosta. Archiwizacja danych jako jedna z najpopularniejszych metod kodowania informacji jest obowiązkowo badana przez informatykę na poziomie szkolnym.
Jak pamiętamy, proces „szyfrowania” plików wbajty są ustandaryzowane. Weźmy standard ASCII. Aby, powiedzmy, zaszyfrować słowo „cześć”, potrzebujemy 6 bajtów, na podstawie liczby liter. Jest to ilość miejsca, jaką plik z tym tekstem zajmie na dysku. Co się stanie, jeśli napiszemy słowo „cześć” 100 razy z rzędu? Nic specjalnego - do tego potrzebujemy odpowiednio 600 bajtów, tyle samo miejsca na dysku. Możemy jednak skorzystać z archiwizatora, który utworzy plik, w którym przy użyciu znacznie mniejszej liczby bajtów zostanie „zaszyfrowane” polecenie, które wygląda mniej więcej tak: „cześć, pomnóż przez 100”. Po przeliczeniu ilości liter w tej wiadomości dochodzimy do wniosku, że do zapisania takiego pliku potrzebujemy tylko 19 bajtów. I tyle samo miejsca na dysku. Podczas „rozpakowywania” pliku archiwum następuje „odszyfrowanie”, a tekst przybiera swoją pierwotną formę z „100 pozdrowieniami”. W ten sposób, korzystając ze specjalnego programu, który wykorzystuje specjalny mechanizm kodowania, możemy zaoszczędzić znaczną ilość miejsca na dysku.
Powyższy proces jest dość uniwersalny: bez względu na stosowane systemy znakowe, zawsze możliwe jest zakodowanie informacji w celu kompresji za pomocą archiwizacji danych.
Jaki jest drugi mechanizm?W pewnym stopniu jest podobny do tego, który jest używany w archiwach. Ale jego podstawową różnicą jest to, że skompresowany plik może zostać wyświetlony przez komputer bez procedury „rozpakowywania”. Jak działa ten mechanizm?
Jak pamiętamy, w swojej pierwotnej formie słowo „cześć”zajmuje 6 bajtów. Możemy jednak pokusić się o lewę i napisać to tak: „prvt”. Wychodzą 4 bajty. Pozostaje tylko „nauczyć” komputer dodawania liter, które usunęliśmy podczas wyświetlania pliku. Trzeba powiedzieć, że w praktyce nie jest konieczne organizowanie procesu „edukacyjnego”. Podstawowe mechanizmy rozpoznawania brakujących znaków są wbudowane w większość nowoczesnych programów komputerowych. Oznacza to, że większość plików, z którymi mamy do czynienia na co dzień, jest już w jakiś sposób „zaszyfrowana” przy użyciu tego algorytmu.
Oczywiście są też systemy „hybrydowe”.kodowanie informacji, umożliwiające kompresję danych przy jednoczesnym zastosowaniu obu powyższych podejść. I prawdopodobnie będą nawet bardziej wydajne pod względem oszczędzania miejsca na dysku niż osobno.
Oczywiście, używając słowa „cześć”, stwierdziliśmytylko podstawowe zasady mechanizmów kompresji danych. W rzeczywistości są znacznie bardziej skomplikowane. Różne systemy kodowania informacji mogą oferować niezwykle złożone mechanizmy „kompresji” plików. Widzimy jednak, jak można zaoszczędzić miejsce na dysku, praktycznie bez uciekania się do pogorszenia jakości informacji na komputerze. Rola kompresji danych jest szczególnie istotna w przypadku korzystania z obrazów, audio i wideo - tego typu dane są bardziej wymagające pod względem zasobów dyskowych.
Jak powiedzieliśmy na samym początku, kodowanie jestto złożone zjawisko. Teraz, gdy rozumiemy podstawowe zasady kodowania danych cyfrowych opartych na bajtach, możemy dotknąć innego obszaru. Wiąże się to z użyciem kodów komputerowych w nieco innych znaczeniach. Tutaj przez „kod” rozumiemy nie ciąg zer i jedynek, ale zbiór różnych liter i symboli (które, jak już wiemy, są już złożone z 0 i 1), co ma praktyczne znaczenie dla życia człowieka. nowoczesna osoba.
W sercu pracy dowolnego programu komputerowego -kod. Jest napisany w języku zrozumiałym dla komputera. Komputer, odszyfrowując kod, wykonuje określone polecenia. Charakterystyczną cechą programu komputerowego z innego rodzaju danych cyfrowych jest to, że kod w nim zawarty jest zdolny do „odszyfrowania” się (użytkownik musi tylko rozpocząć ten proces).

Inną cechą programów jest względnyelastyczność użytego kodu. Oznacza to, że osoba może zlecić komputerowi te same zadania, używając wystarczająco dużego zestawu „wyrażeń” i, jeśli to konieczne, w innym języku.
Kolejny praktycznie istotny obszar zastosowańkod alfabetyczny - tworzenie i formatowanie dokumentów. Z reguły proste wyświetlanie znaków na ekranie nie wystarcza z punktu widzenia praktycznego znaczenia korzystania z komputera. W większości przypadków tekst powinien być budowany czcionką o określonym kolorze i rozmiarze wraz z dodatkowymi elementami (np. tabelami). Wszystkie te parametry są ustawione, podobnie jak w przypadku programów, w specjalnych językach zrozumiałych dla komputera. Komputer, rozpoznając „polecenia”, wyświetla dokumenty dokładnie tak, jak chce użytkownik. Ponadto teksty mogą być formatowane w ten sam sposób, jak w przypadku programów, przy użyciu różnych zestawów „fraz”, a nawet w różnych językach.
Istnieje jednak zasadnicza różnica między kodamido dokumentów i programów komputerowych. Polega na tym, że ci pierwsi nie potrafią się rozszyfrować. Programy innych firm są zawsze wymagane do otwierania sformatowanych plików tekstowych.
Inna interpretacja terminu „kod”w przypadku komputerów jest to szyfrowanie danych. Powyżej użyliśmy tego słowa jako synonimu terminu „kodowanie” i jest to dopuszczalne. W tym przypadku przez szyfrowanie rozumiemy inny rodzaj zjawiska. Mianowicie kodowanie danych cyfrowych w celu uniemożliwienia dostępu do nich innym osobom. Ochrona plików komputerowych to najważniejszy obszar działalności w dziedzinie IT. Jest to właściwie odrębna dyscyplina naukowa, do której zalicza się również informatyka szkolna. Szyfrowanie plików w celu zapobieżenia nieautoryzowanemu dostępowi to zadanie, które już w dzieciństwie jest uświadamiane obywatelom nowoczesnych krajów.

Jak działają mechanizmy, dzięki którym?wykonane szyfrowanie danych? W zasadzie jest tak prosty i zrozumiały, jak wszystkie poprzednie, które rozważaliśmy. Kodowanie to proces, który można łatwo wytłumaczyć za pomocą podstawowych zasad logiki.
Załóżmy, że musimy wysłać wiadomość„Iwanow jedzie do Pietrowa”, aby nikt nie mógł go przeczytać. Ufamy komputerowi, że zaszyfruje wiadomość i zobaczy wynik: „10-3-1-15-16-3-10-5-7-20-11-17-6-20-18-3-21”. Ten kod jest oczywiście bardzo prosty: każda cyfra odpowiada liczbie porządkowej liter naszej frazy w alfabecie. „I” jest na 10 miejscu, „B” – na 3, „A” – na 1 itd. Ale współczesne komputerowe systemy kodowania potrafią szyfrować dane w taki sposób, że znalezienie do nich klucza będzie niezwykle trudne.


