


Der genetische Code ist in Codons ausgedrücktein System zur Kodierung von Informationen über die Struktur von Proteinen, die allen lebenden Organismen des Planeten inhärent sind. Seine Entschlüsselung dauerte ein Jahrzehnt, aber die Wissenschaft verstand fast ein Jahrhundert, dass es existiert. Universalität, Spezifität, Einpunktigkeit und vor allem die Entartung des genetischen Codes haben eine wichtige biologische Bedeutung.

Das Problem der Codierung der genetischen Informationwar schon immer der Schlüssel zur Biologie. Die Wissenschaft bewegte sich relativ langsam zur Matrixstruktur des genetischen Codes. Seit der Entdeckung von J. Watson und F. Crick im Jahr 1953 der Doppelhelix-Struktur von DNA begann die Phase der Lösung der Struktur des Codes, die den Glauben an die Größe der Natur auslöste. Die lineare Struktur von Proteinen und dieselbe Struktur von DNA implizierte das Vorhandensein eines genetischen Codes als Korrespondenz zweier Texte, die jedoch mit verschiedenen Alphabeten aufgezeichnet wurden. Wenn das Alphabet der Proteine bekannt war, wurden DNA-Zeichen von Biologen, Physikern und Mathematikern untersucht.
Es macht keinen Sinn, alle Schritte zur Lösung dieses Problems zu beschreibenRätsel Ein direktes Experiment, das die eindeutige und konsistente Übereinstimmung der DNA-Codons mit den Aminosäuren eines Proteins bestätigte, wurde 1964 von C. Janowski und S. Brenner durchgeführt. Und dann - die Zeit der Dekodierung des genetischen Codes in vitro (in vitro) unter Verwendung von Proteinsynthesetechniken in zellfreien Strukturen.
Полностью расшифрованный код E.Coli wurde 1966 auf einem Symposium von Biologen in Cold Spring Harbor (USA) verkündet. Dann wurde die Redundanz (Entartung) des genetischen Codes aufgezeigt. Was dies bedeutet, wird ganz einfach erklärt.

Получение данных о расшифровке наследственного Der Kodex ist zu einem der bedeutendsten Ereignisse des letzten Jahrhunderts geworden. Heute erforscht die Wissenschaft die Mechanismen der molekularen Codierung und ihrer Systemmerkmale sowie einen Überfluss an Zeichen, in denen die Eigenschaft der Entartung des genetischen Codes zum Ausdruck kommt. Ein gesonderter Forschungszweig ist die Entstehung und Entwicklung des Kodierungssystems für Erbmaterial. Der Nachweis einer Verbindung zwischen Polynukleotiden (DNA) und Polypeptiden (Proteinen) gab der Entwicklung der Molekularbiologie Anstoß. Und das wiederum Biotechnologie, Bioengineering, Entdeckungen in der Pflanzenzüchtung und Pflanzenzüchtung.
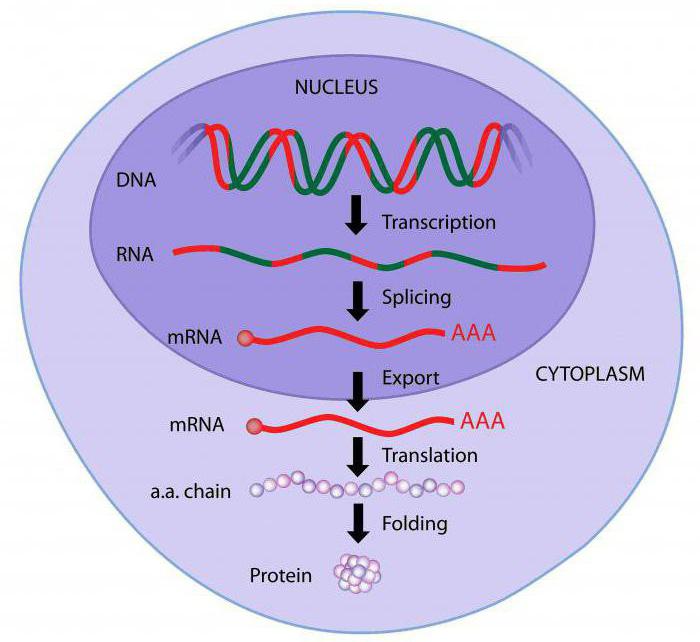
Das wichtigste Dogma der Molekularbiologie ist, dass Informationen von der DNA zur Boten-RNA und dann von dieser zum Protein übertragen werden. In umgekehrter Richtung ist der Transfer von RNA zu DNA und von RNA zu einer anderen RNA möglich.
Но матрицей или основой всегда остается ДНК.Alle anderen grundlegenden Merkmale der Informationsübertragung spiegeln diese Matrixcharakteristik der Übertragung wider. Übertragung mittels Synthese auf die Matrix anderer Moleküle, die zur Struktur der Reproduktion erblicher Informationen wird.
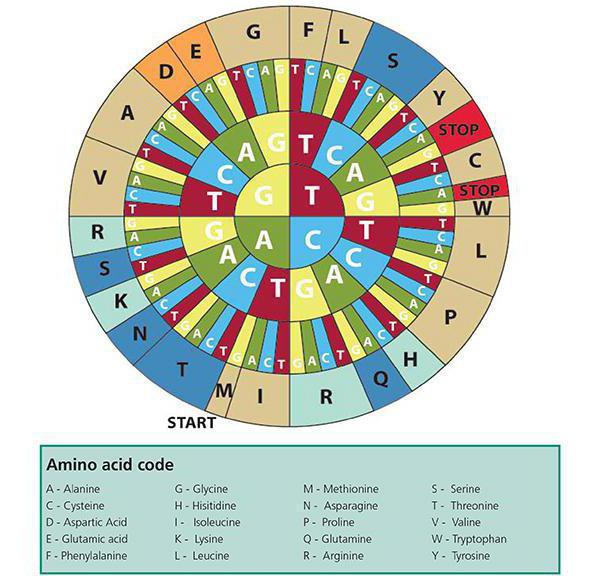
Lineare Kodierung der Struktur von Proteinmolekülendurchgeführt unter Verwendung komplementärer Kodons (Tripletts) von Nukleotiden, von denen nur 4 (Adein, Guanin, Cytosin, Thymin (Uracil)), was spontan zur Bildung einer anderen Nukleotidkette führt. Die gleiche Anzahl und chemische Komplementarität der Nukleotide ist die Hauptbedingung für eine solche Synthese. Wenn jedoch ein Proteinmolekül gebildet wird, ist die Qualität der Einhaltung der Quantität und Qualität der Monomere nicht (DNA-Nukleotide sind Proteinaminosäuren). Dies ist der natürliche Erbcode - das System für die Aufnahme in der Nukleotidsequenz (Codons) der Aminosäuresequenz in einem Protein.
Der genetische Code hat mehrere Eigenschaften:
Wir geben eine kurze Beschreibung, die sich auf den biologischen Wert konzentriert.
Каждой из 61 аминокислоты соответствует один Triplet (Troika) von Nukleotiden. Drei Triolen enthalten keine Informationen über die Aminosäure und sind Stop-Codons. Jedes Nukleotid in der Kette ist Teil des Tripletts und existiert nicht für sich. Am Ende und am Anfang einer Kette von Nukleotiden, die für ein Protein verantwortlich sind, gibt es Stopcodons. Sie beginnen oder stoppen die Translation (Proteinmolekülsynthese).
Jedes Codon (Triplett) codiert nur einAminosäure. Jedes Triplet hängt nicht vom Nachbarn ab und überlappt sich nicht. Ein Nukleotid kann nur in einem Triplett in einer Kette enthalten sein. Die Proteinsynthese verläuft immer nur in eine Richtung, die von Stop-Codons reguliert wird.
Jedes Nukleotid-Triplett kodiert für einsAminosäure. Nur 64 Nukleotide, 61 davon - kodieren Aminosäuren (Sense-Codons) und drei sind sinnlos, das heißt, sie kodieren nicht für die Aminosäure (Stop-Codons). Die Redundanz (Entartung) des genetischen Codes liegt in der Tatsache, dass in jedem Triplett Substitutionen vorgenommen werden können - radikal (führen zum Ersatz von Aminosäuren) und konservativ (ändern Sie die Klasse der Aminosäuren nicht). Es ist leicht zu berechnen, dass, wenn in einem Triplett 9 Substitutionen vorgenommen werden können (1, 2 und 3-Position), jedes Nukleotid durch 4 - 1 = 3 andere Varianten ersetzt werden kann, die Gesamtzahl der möglichen Nukleotidsubstitutionen 61 zu 9 = 549 ist.
Die Entartung des genetischen Codes manifestiert sich inDiese 549 Varianten sind viel mehr, als es für die Kodierung der Information auf 21 Aminosäuren erforderlich ist. Gleichzeitig führen 239 von 549 Varianten zur Bildung von Stop-Codons, 134 + 230-Substitutionen sind konservativ und 162 Substitutionen sind radikal.

Если два кодона имеют два одинаковых первых Nukleotid, und der Rest wird durch Nukleotide der gleichen Klasse (Purin oder Pyrimidin) dargestellt, sie tragen Informationen über die gleiche Aminosäure. Dies ist die Regel der Entartung oder Redundanz des genetischen Codes. Zwei Ausnahmen - AUA und CAA - kodieren die erste für Methionin, obwohl es Isoleucin hätte, und die zweite - ein Stop-Codon, obwohl Tryptophan kodiert werden musste.
Именно эти два свойства генетического кода имеют der größte biologische Wert. Alle oben aufgeführten Eigenschaften sind kennzeichnend für die Erbinformation aller Lebewesen auf unserem Planeten.

Die Entartung des genetischen Codes hatadaptiver Wert, als wiederholte Vervielfältigung eines einzelnen Aminosäurecodes. Zusätzlich bedeutet dies eine Abnahme der Signifikanz (Degeneration) des dritten Nukleotids im Codon. Diese Option minimiert den Mutationsschaden in der DNA, was zu groben Verletzungen der Struktur des Proteins führen würde. Dies ist ein Abwehrmechanismus lebender Organismen des Planeten.


