


Fremkomsten af computerteknologi i voresmodernitet har markeret en informationsrevolution på alle områder af menneskelig aktivitet. Men for at forhindre, at al information bliver unødvendig skrald på det globale internet, blev der opfundet et databasesystem, i hvilket materiale sorteres, systematiseres, hvilket resulterer i, at de let kan findes og præsenteres til efterfølgende behandling. Der er tre hovedtyper - relationsdatabaser, hierarkiske, netværk.
At gå tilbage til oprindelsen af databaser er det værdat sige, at denne proces var ret kompleks, den stammer fra udviklingen af programmerbart udstyr til informationsbehandling. Derfor er det ikke overraskende, at antallet af deres modeller i øjeblikket når mere end 50, men de vigtigste anses for at være hierarkiske, relationelle og netværk, som stadig bruges i vid udstrækning. Hvad er de?
Den hierarkiske database har et trælignendestruktur og er sammensat af data på forskellige niveauer, mellem hvilke der er forbindelser. DB-netværksmodellen er et mere komplekst mønster. Dens struktur ligner en hierarkisk, og ordningen udvides og forbedres. Forskellen mellem dem er, at de arvelige data i en hierarkisk model kun kan have forbindelse med en forfader, mens netværksdataene kan have flere. Strukturen i en relationsdatabase er meget mere kompleks. Derfor bør det analyseres mere detaljeret.

Denne model blev udviklet i 1970'erne.af Edgar Codd, Doctor of Science. Det er en logisk struktureret tabel med felter, der beskriver dataene, deres forhold til hinanden, de operationer, der udføres på dem og vigtigst af alt de regler, der garanterer deres integritet. Hvorfor kaldes modellen relationel? Det er baseret på relationer (fra lat. Relatio) mellem data. Der er mange definitioner for denne type database. Relationelle tabeller med information er meget lettere at organisere og behandle end i et netværk eller en hierarkisk model. Hvordan kan dette gøres? Det er nok at kende funktionerne, modellens struktur og egenskaberne ved relationelle tabeller.

For at oprette dit eget DBMS skal dubrug et af modelleringsværktøjerne, tænk over, hvilke oplysninger du har brug for at arbejde med, design tabeller og relationelle enkelt- og multiple forhold mellem data, udfyld enhedsceller og indstil primære, udenlandske nøgler.
Tabelmodellering og relationsdesigndatabaser produceres gennem gratis værktøjer såsom Workbench, PhpMyAdmin, Case Studio, dbForge Studio. Efter detaljeret design skal du gemme den grafisk klar relationelle model og oversætte den til færdiglavet SQL-kode. På dette stadium kan du begynde at arbejde med datasortering, behandling og systematisering.
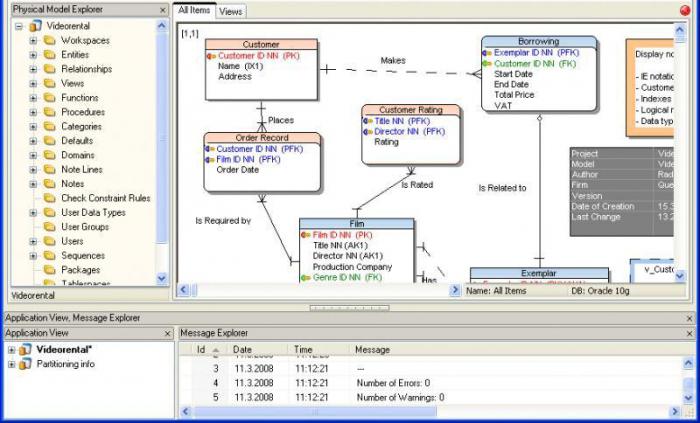
Hver kilde beskriver sine elementer på sin egen måde, så for mindre forvirring vil jeg gerne give et lille tip:

For at komme til egenskaberne for en relationsdatabase skal du vide, hvilke grundlæggende komponenter den består af, og hvad de er beregnet til.
Nu ved du at kende de bestanddele, der findes i tabellen, kan du gå til egenskaberne for databasens relationelle model:
Baseret på egenskaberne ved en relationel DBMS er det klart, at attributværdierne skal være af samme type og længde. Lad os overveje funktionerne i attributværdierne.
Feltnavne skal være unikke inden foren enhed. Relational database attribut eller felttyper beskriver, hvilke kategoridata der er gemt i enhedsfelter. Et relationsdatabasefelt skal have en fast størrelse i tegn. Parametrene og formatet for attributværdier bestemmer, hvordan dataene korrigeres i dem. Der er også sådan en ting som "maske" eller "input mønster". Det er beregnet til at definere konfigurationen af dataindtastning i attributværdien. Det er bydende nødvendigt, at der udstedes en fejlmeddelelse, når du skriver en forkert datatype i et felt. Der pålægges også nogle begrænsninger for elementerne i felterne - betingelser for kontrol af nøjagtigheden og fejlfri dataindtastning. Der er en påkrævet attributværdi, der entydigt skal udfyldes med data. Nogle attributstrenge kan udfyldes med NULL-værdier. Indtastning af tomme data i feltattributter er tilladt. Ligesom fejlmeddelelsen er der værdier, der automatisk udfyldes af systemet - dette er standarddata. Et indekseret felt er beregnet til at fremskynde søgningen efter data.

| Attributnavn 1 | Attributnavn 2 | Attributnavn 3 | Attributnavn 4 | Attributnavn 5 |
| Vare_1_1 | Vare_1_2 | Vare_1_3 | Vare_1_4 | Vare_1_5 |
| Vare_2_1 | Vare_2_2 | Vare_2_3 | Vare_2_4 | Vare_2_5 |
| Vare_3_1 | Vare_3_2 | Vare_3_3 | Vare_3_4 | Vare_3_5 |
For en detaljeret forståelse af kontrolsystemetModeller, der bruger SQL, er den bedste måde at se skemaet på ved eksempel. Vi ved allerede, hvad en relationsdatabase er. En post i hver tabel er et dataelement. For at forhindre dataredundans er det nødvendigt at udføre normaliseringsoperationer.
1. Værdien af feltnavnet for en relationstabel skal være unik, unik (den første normale form er 1NF).
2. For en tabel, der allerede er reduceret til 1NF, skal navnet på en ikke-identificerende kolonne afhænge af den unikke identifikator for tabellen (2NF).
3. For hele tabellen, der allerede er i 2NF, kan hvert ikke-identificerende felt ikke afhænge af et element af en anden ukendt værdi (enhed 3NF).
Der er to hovedtyper af relationelle tabelforhold:

Primære og sekundære nøgler definererpotentielle databaseforhold. Relationslinks i en datamodel kan kun have en potentiel nøgle, dette vil være den primære nøgle. Hvordan er han? En primær nøgle er en enhedskolonne eller et sæt attributter, der giver dig adgang til dataene for en bestemt række. Det skal være unikt, unikt, og dets felter kan ikke indeholde tomme værdier. Hvis den primære nøgle kun består af en attribut, kaldes den simpel, ellers vil den være en komponent.
Ud over den primære nøgle er der også en ekstern(fremmed nøgle). Mange forstår ikke, hvad forskellen er mellem dem. Lad os se nærmere på dem ved hjælp af et eksempel. Så der er to tabeller: "Dekanskontoret" og "Studerende". Enheden "Dean's office" indeholder felterne: "Student ID", "Full name" og "Group". Tabellen "Studerende" har attributværdier som "Navn", "Gruppe" og "Gennemsnit". Da studerende-id ikke kan være det samme for flere studerende, vil dette felt være den primære nøgle. "Fuldt navn" og "Gruppe" fra "Studerende" -tabellen kan være den samme for flere personer. De henviser til ID-nummeret på den studerende fra "Dekanatens kontor" -enhed, derfor kan de bruges som en fremmed nøgle.
For klarhedens skyld vil vi give et simpelt eksempel på en relationsdatabasemodel bestående af to enheder. Der er en tabel kaldet "Dekanat".
Essence "Dekanat" | ||
studiekort | Fulde navn | Gruppen |
111 | Ivanov Oleg Petrovich | IN-41 |
222 | Ilya Lazarev | IN-72 |
333 | Konoplev Petr Vasilievich | IN-41 |
444 | Kushnereva Natalia Igorevna | IN-72 |
Du skal oprette forbindelser for at kommefuldgyldig relationsdatabase. Posten "IN-41", ligesom "IN-72", kan være til stede mere end én gang i "Dean's office" -pladen, og de studerendes efternavn, fornavn og patronym kan i sjældne tilfælde falde sammen, så disse felter kan ikke være lavet den primære nøgle. Lad os vise enheden "Studerende".
"Studerende" tabel | |||
Fulde navn | Gruppen | Gennemsnitlig karakter | telefon |
Ivanov Oleg Petrovich | IN-41 | 3,0 | 2-27-36 |
Ilya Lazarev | IN-72 | 3,8 | 2-36-82 |
Konoplev Petr Vasilievich | IN-41 | 3,9 | 2-54-78 |
Kushnereva Natalia Igorevna | IN-72 | 4,7 | 2-65-25 |
Som vi kan se, typer felter i relationsdatabaserhelt anderledes. Der er både digitale og symbolske poster. Derfor skal værdierne for heltal, char, vachar, dato og andre specificeres i attributindstillingerne. I tabellen "Dean's office" er kun studerende-ID en unik værdi. Dette felt kan tages som en primær nøgle. Fuldt navn, gruppe og telefonnummer fra "Studerende" -enheden kan tages som en fremmed nøgle, der henviser til studerendes id. Forbindelsen er oprettet. Dette er et eksempel på en en-til-en forholdsmodel. Hypotetisk er en af tabellerne overflødig, de kan let kombineres til en enhed. For at forhindre, at elev-ID-numre bliver almindeligt kendt, er eksistensen af to tabeller ret realistisk.


